1 Example of Categorical Distribution
Vocabulary:
V=3, {dog, cat,bird}Num Observations:
N=9Categories:
C=3, {negative, neutral, positive}Dataset:
D={(class1, word1)…}
1.1 Formula for parameter estimation

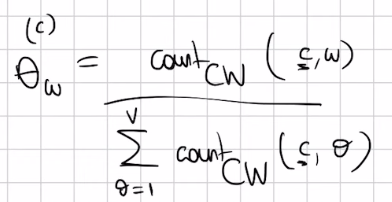
Here the denominator means to count all pairs that have the same class
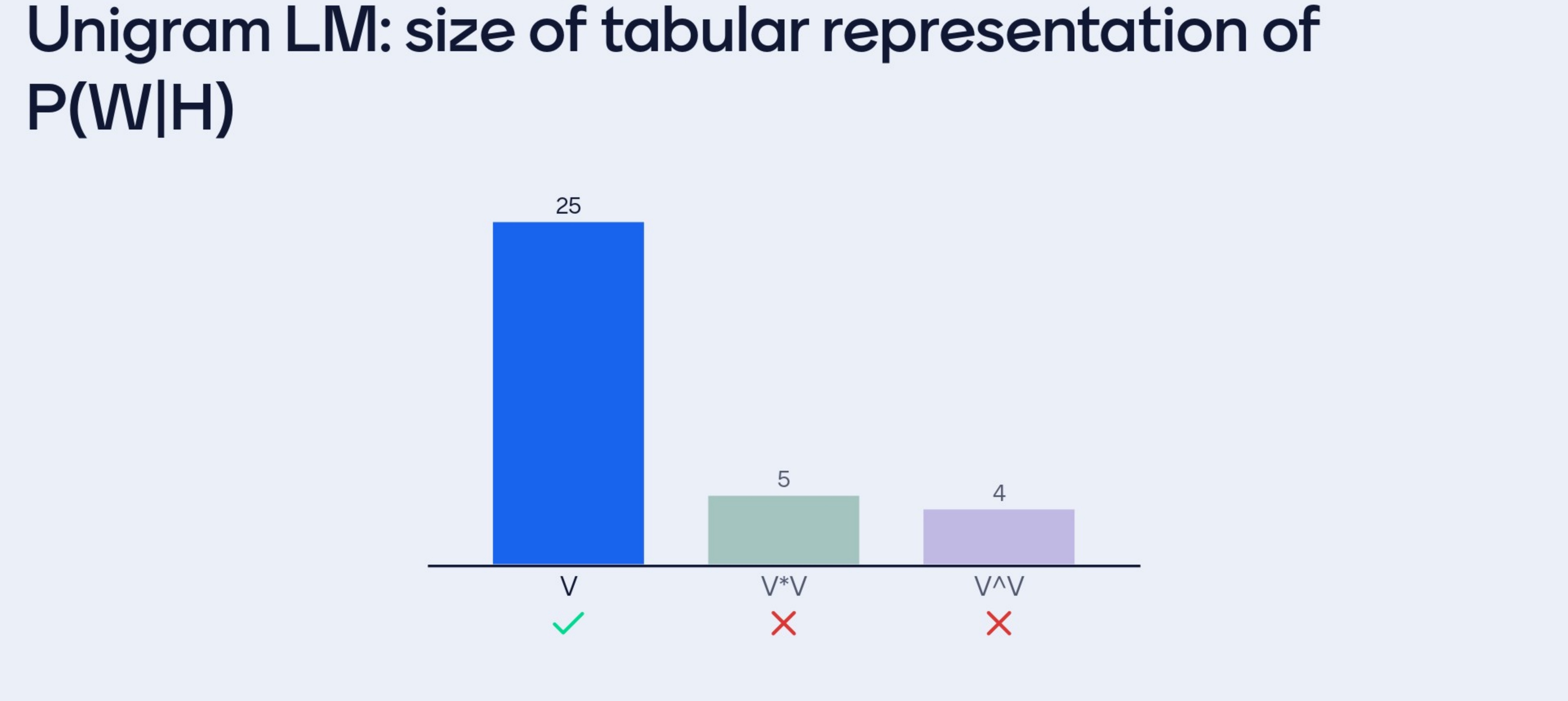
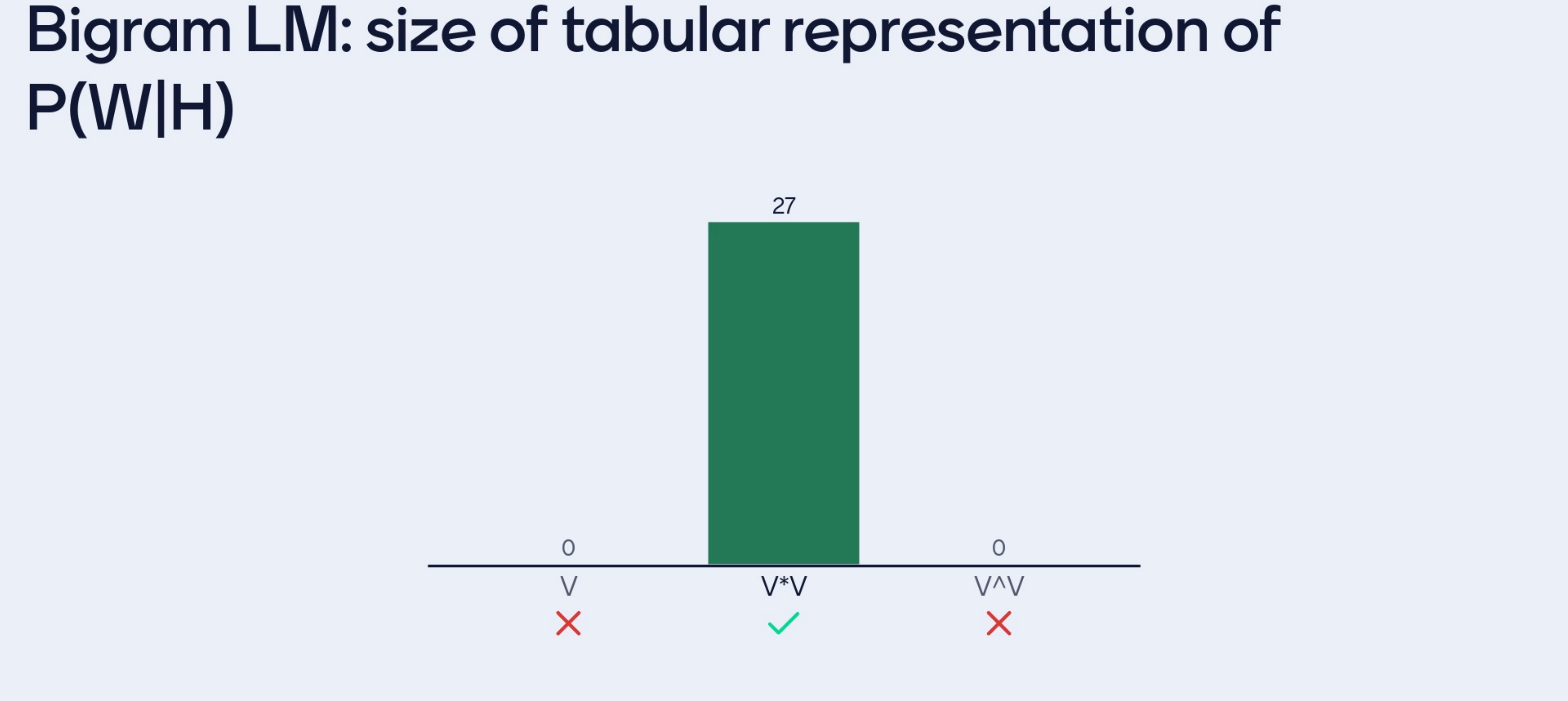
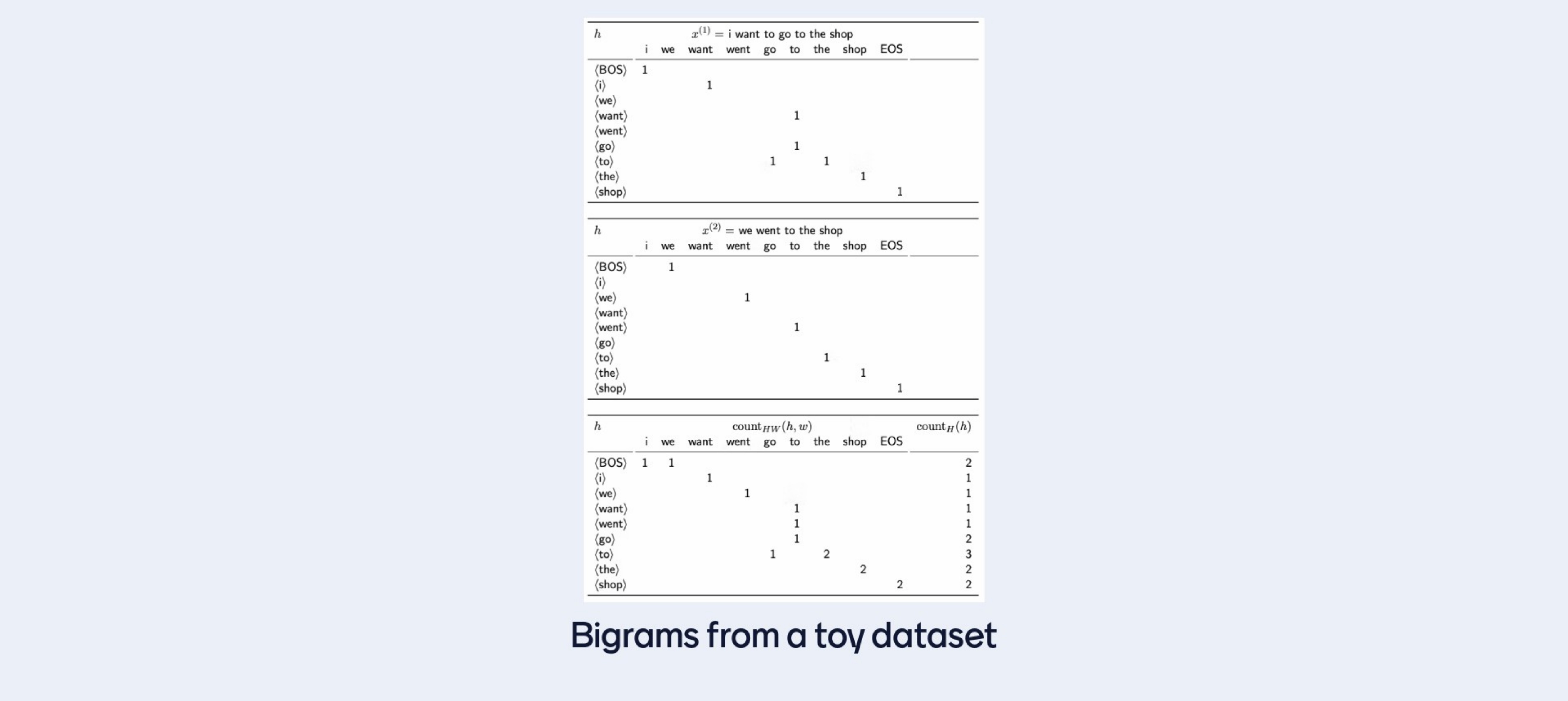
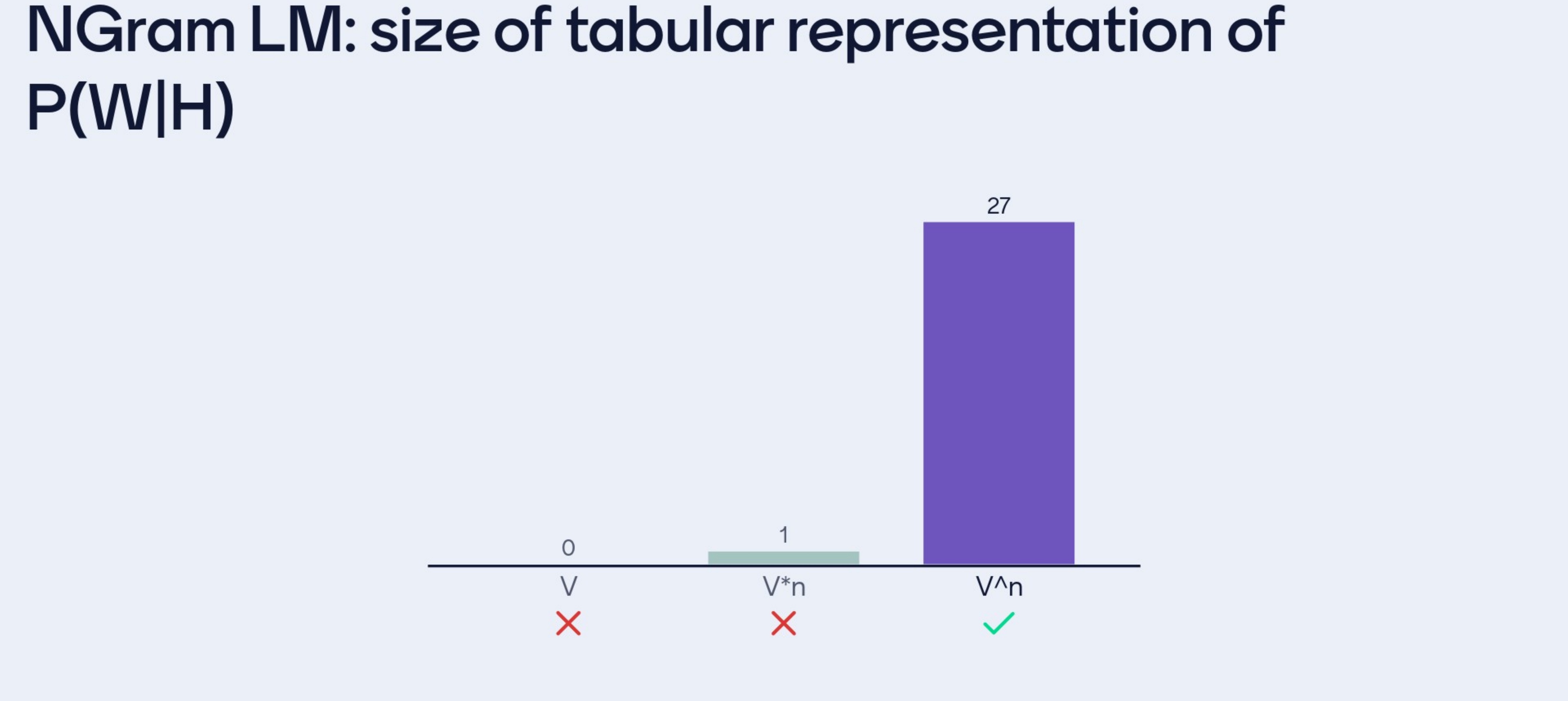
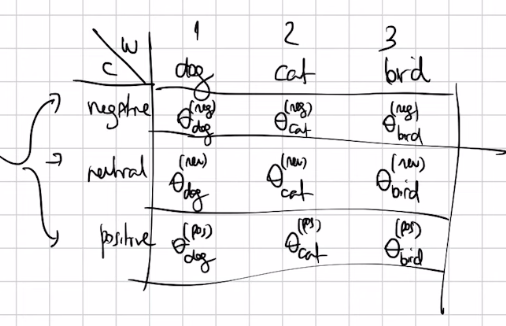
- Tabular Representation:
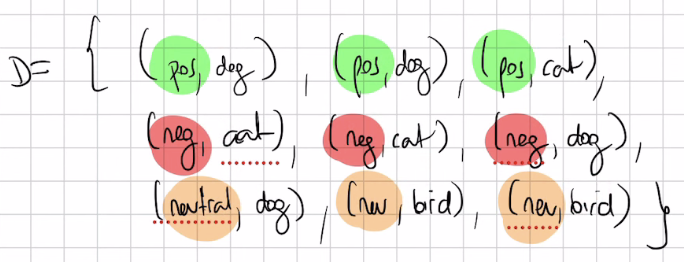
- The dataset:
- Maximum Likelihood Estimates:
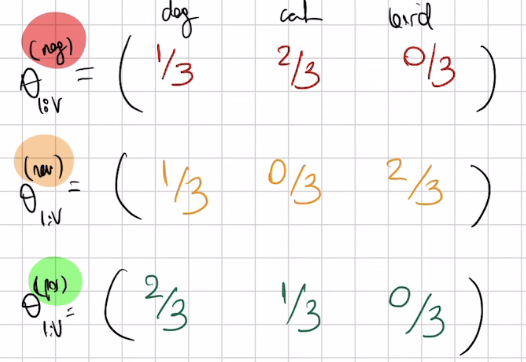
2 Smoothing

For instance if I have to compute the prob for \(\theta_{bird}^{neg}=\frac{0}{3}\) then because I will have a zero probability then I can use only the count plus some constant (smoothing)so that the probability estimate does not become \(0\)
For instance: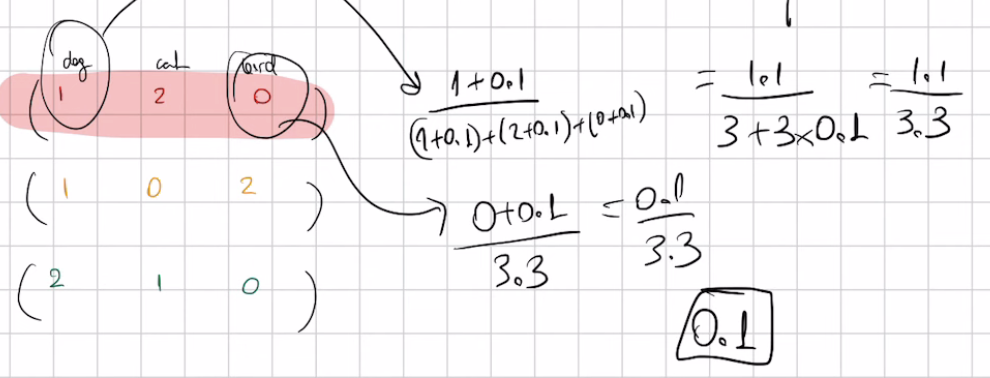
Here 0.1 is the smoothing constant
So if not smoothing then use probs, if use smoothing the we use the counts